Initial commit for AI Medical project base
This commit is contained in:
parent
5876dab5a1
commit
a7c54a47b8
8
.idea/.gitignore
generated
vendored
Normal file
8
.idea/.gitignore
generated
vendored
Normal file
@ -0,0 +1,8 @@
|
|||||||
|
# Default ignored files
|
||||||
|
/shelf/
|
||||||
|
/workspace.xml
|
||||||
|
# Editor-based HTTP Client requests
|
||||||
|
/httpRequests/
|
||||||
|
# Datasource local storage ignored files
|
||||||
|
/dataSources/
|
||||||
|
/dataSources.local.xml
|
||||||
6
.idea/inspectionProfiles/Project_Default.xml
generated
Normal file
6
.idea/inspectionProfiles/Project_Default.xml
generated
Normal file
@ -0,0 +1,6 @@
|
|||||||
|
<component name="InspectionProjectProfileManager">
|
||||||
|
<profile version="1.0">
|
||||||
|
<option name="myName" value="Project Default" />
|
||||||
|
<inspection_tool class="Eslint" enabled="true" level="WARNING" enabled_by_default="true" />
|
||||||
|
</profile>
|
||||||
|
</component>
|
||||||
9
.idea/misc.xml
generated
Normal file
9
.idea/misc.xml
generated
Normal file
@ -0,0 +1,9 @@
|
|||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<project version="4">
|
||||||
|
<component name="Black">
|
||||||
|
<option name="sdkName" value="Python 3.12" />
|
||||||
|
</component>
|
||||||
|
<component name="ProjectRootManager" version="2" languageLevel="JDK_21" default="true" project-jdk-name="temurin-21 (2)" project-jdk-type="JavaSDK">
|
||||||
|
<output url="file://$PROJECT_DIR$/out" />
|
||||||
|
</component>
|
||||||
|
</project>
|
||||||
8
.idea/modules.xml
generated
Normal file
8
.idea/modules.xml
generated
Normal file
@ -0,0 +1,8 @@
|
|||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<project version="4">
|
||||||
|
<component name="ProjectModuleManager">
|
||||||
|
<modules>
|
||||||
|
<module fileurl="file://$PROJECT_DIR$/.idea/monorepo-starter-template.iml" filepath="$PROJECT_DIR$/.idea/monorepo-starter-template.iml" />
|
||||||
|
</modules>
|
||||||
|
</component>
|
||||||
|
</project>
|
||||||
9
.idea/monorepo-starter-template.iml
generated
Normal file
9
.idea/monorepo-starter-template.iml
generated
Normal file
@ -0,0 +1,9 @@
|
|||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<module type="JAVA_MODULE" version="4">
|
||||||
|
<component name="NewModuleRootManager" inherit-compiler-output="true">
|
||||||
|
<exclude-output />
|
||||||
|
<content url="file://$MODULE_DIR$" />
|
||||||
|
<orderEntry type="jdk" jdkName="Python 3.12" jdkType="Python SDK" />
|
||||||
|
<orderEntry type="sourceFolder" forTests="false" />
|
||||||
|
</component>
|
||||||
|
</module>
|
||||||
6
.idea/vcs.xml
generated
Normal file
6
.idea/vcs.xml
generated
Normal file
@ -0,0 +1,6 @@
|
|||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<project version="4">
|
||||||
|
<component name="VcsDirectoryMappings">
|
||||||
|
<mapping directory="" vcs="Git" />
|
||||||
|
</component>
|
||||||
|
</project>
|
||||||
103
ai-medical/app.py
Normal file
103
ai-medical/app.py
Normal file
@ -0,0 +1,103 @@
|
|||||||
|
import os
|
||||||
|
import tempfile
|
||||||
|
import torch
|
||||||
|
import logging
|
||||||
|
import boto3
|
||||||
|
from botocore.client import Config
|
||||||
|
from fastapi import FastAPI, HTTPException
|
||||||
|
from contextlib import asynccontextmanager
|
||||||
|
from pydantic_settings import BaseSettings
|
||||||
|
|
||||||
|
|
||||||
|
# --- Logging setup ---
|
||||||
|
logger = logging.getLogger("uvicorn")
|
||||||
|
logging.basicConfig(level=logging.INFO)
|
||||||
|
|
||||||
|
|
||||||
|
# --- 1. Settings ---
|
||||||
|
class Settings(BaseSettings):
|
||||||
|
MINIO_ENDPOINT: str = "http://localhost:9000"
|
||||||
|
MINIO_ACCESS_KEY: str = "minio_admin"
|
||||||
|
MINIO_SECRET_KEY: str = "minio_p@ssw0rd!"
|
||||||
|
MODEL_BUCKET: str = "models"
|
||||||
|
MODEL_FILE: str = "spleen_ct_spleen_model.ts"
|
||||||
|
DEVICE: str = "cuda" if torch.cuda.is_available() else "cpu"
|
||||||
|
|
||||||
|
model_config = {'env_file': '.env', 'env_file_encoding': 'utf-8'}
|
||||||
|
|
||||||
|
|
||||||
|
settings = Settings()
|
||||||
|
model = None
|
||||||
|
|
||||||
|
|
||||||
|
# --- 2. Load Model Function ---
|
||||||
|
def load_monai_model():
|
||||||
|
"""โหลด TorchScript model จาก MinIO"""
|
||||||
|
global model
|
||||||
|
try:
|
||||||
|
logger.info(f"Loading model '{settings.MODEL_FILE}' from MinIO...")
|
||||||
|
|
||||||
|
s3 = boto3.client(
|
||||||
|
"s3",
|
||||||
|
endpoint_url=settings.MINIO_ENDPOINT,
|
||||||
|
aws_access_key_id=settings.MINIO_ACCESS_KEY,
|
||||||
|
aws_secret_access_key=settings.MINIO_SECRET_KEY,
|
||||||
|
config=Config(signature_version="s3v4", connect_timeout=5, read_timeout=10)
|
||||||
|
)
|
||||||
|
|
||||||
|
with tempfile.TemporaryDirectory() as temp_dir:
|
||||||
|
local_path = os.path.join(temp_dir, settings.MODEL_FILE)
|
||||||
|
s3.download_file(settings.MODEL_BUCKET, settings.MODEL_FILE, local_path)
|
||||||
|
|
||||||
|
model_loaded = torch.jit.load(local_path, map_location=settings.DEVICE)
|
||||||
|
model_loaded.eval()
|
||||||
|
model = model_loaded
|
||||||
|
|
||||||
|
logger.info(f"Model '{settings.MODEL_FILE}' loaded successfully on {settings.DEVICE}")
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"Model load failed: {e}")
|
||||||
|
raise HTTPException(status_code=500, detail=f"Model Initialization Failed: {e}")
|
||||||
|
|
||||||
|
|
||||||
|
# --- 3. Lifespan Event Handler (แทน @app.on_event) ---
|
||||||
|
@asynccontextmanager
|
||||||
|
async def lifespan(app: FastAPI):
|
||||||
|
global model
|
||||||
|
# Startup
|
||||||
|
load_monai_model()
|
||||||
|
yield
|
||||||
|
# Shutdown (optional cleanup)
|
||||||
|
model = None
|
||||||
|
logger.info("Model unloaded from memory.")
|
||||||
|
|
||||||
|
|
||||||
|
# --- 4. Create FastAPI App ---
|
||||||
|
app = FastAPI(
|
||||||
|
title="MONAI Model API",
|
||||||
|
description="FastAPI serving MONAI TorchScript model from MinIO",
|
||||||
|
version="1.0.0",
|
||||||
|
lifespan=lifespan
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
# --- 5. Root Endpoint ---
|
||||||
|
@app.get("/")
|
||||||
|
async def read_root():
|
||||||
|
return {
|
||||||
|
"status": "Service Running",
|
||||||
|
"model_loaded": model is not None,
|
||||||
|
"model_name": settings.MODEL_FILE,
|
||||||
|
"device": settings.DEVICE,
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
# --- 6. Reload Endpoint ---
|
||||||
|
@app.post("/reload")
|
||||||
|
async def reload_model():
|
||||||
|
"""รีโหลดโมเดลจาก MinIO โดยไม่ต้อง restart service"""
|
||||||
|
try:
|
||||||
|
load_monai_model()
|
||||||
|
return {"message": f"Model '{settings.MODEL_FILE}' reloaded successfully"}
|
||||||
|
except Exception as e:
|
||||||
|
raise HTTPException(status_code=500, detail=str(e))
|
||||||
36
ai-medical/models/spleen_ct_segmentation/.gitattributes
vendored
Normal file
36
ai-medical/models/spleen_ct_segmentation/.gitattributes
vendored
Normal file
@ -0,0 +1,36 @@
|
|||||||
|
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.model filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||||
|
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
models/model.ts filter=lfs diff=lfs merge=lfs -text
|
||||||
201
ai-medical/models/spleen_ct_segmentation/LICENSE
Normal file
201
ai-medical/models/spleen_ct_segmentation/LICENSE
Normal file
@ -0,0 +1,201 @@
|
|||||||
|
Apache License
|
||||||
|
Version 2.0, January 2004
|
||||||
|
http://www.apache.org/licenses/
|
||||||
|
|
||||||
|
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||||
|
|
||||||
|
1. Definitions.
|
||||||
|
|
||||||
|
"License" shall mean the terms and conditions for use, reproduction,
|
||||||
|
and distribution as defined by Sections 1 through 9 of this document.
|
||||||
|
|
||||||
|
"Licensor" shall mean the copyright owner or entity authorized by
|
||||||
|
the copyright owner that is granting the License.
|
||||||
|
|
||||||
|
"Legal Entity" shall mean the union of the acting entity and all
|
||||||
|
other entities that control, are controlled by, or are under common
|
||||||
|
control with that entity. For the purposes of this definition,
|
||||||
|
"control" means (i) the power, direct or indirect, to cause the
|
||||||
|
direction or management of such entity, whether by contract or
|
||||||
|
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||||
|
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||||
|
|
||||||
|
"You" (or "Your") shall mean an individual or Legal Entity
|
||||||
|
exercising permissions granted by this License.
|
||||||
|
|
||||||
|
"Source" form shall mean the preferred form for making modifications,
|
||||||
|
including but not limited to software source code, documentation
|
||||||
|
source, and configuration files.
|
||||||
|
|
||||||
|
"Object" form shall mean any form resulting from mechanical
|
||||||
|
transformation or translation of a Source form, including but
|
||||||
|
not limited to compiled object code, generated documentation,
|
||||||
|
and conversions to other media types.
|
||||||
|
|
||||||
|
"Work" shall mean the work of authorship, whether in Source or
|
||||||
|
Object form, made available under the License, as indicated by a
|
||||||
|
copyright notice that is included in or attached to the work
|
||||||
|
(an example is provided in the Appendix below).
|
||||||
|
|
||||||
|
"Derivative Works" shall mean any work, whether in Source or Object
|
||||||
|
form, that is based on (or derived from) the Work and for which the
|
||||||
|
editorial revisions, annotations, elaborations, or other modifications
|
||||||
|
represent, as a whole, an original work of authorship. For the purposes
|
||||||
|
of this License, Derivative Works shall not include works that remain
|
||||||
|
separable from, or merely link (or bind by name) to the interfaces of,
|
||||||
|
the Work and Derivative Works thereof.
|
||||||
|
|
||||||
|
"Contribution" shall mean any work of authorship, including
|
||||||
|
the original version of the Work and any modifications or additions
|
||||||
|
to that Work or Derivative Works thereof, that is intentionally
|
||||||
|
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||||
|
or by an individual or Legal Entity authorized to submit on behalf of
|
||||||
|
the copyright owner. For the purposes of this definition, "submitted"
|
||||||
|
means any form of electronic, verbal, or written communication sent
|
||||||
|
to the Licensor or its representatives, including but not limited to
|
||||||
|
communication on electronic mailing lists, source code control systems,
|
||||||
|
and issue tracking systems that are managed by, or on behalf of, the
|
||||||
|
Licensor for the purpose of discussing and improving the Work, but
|
||||||
|
excluding communication that is conspicuously marked or otherwise
|
||||||
|
designated in writing by the copyright owner as "Not a Contribution."
|
||||||
|
|
||||||
|
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||||
|
on behalf of whom a Contribution has been received by Licensor and
|
||||||
|
subsequently incorporated within the Work.
|
||||||
|
|
||||||
|
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
copyright license to reproduce, prepare Derivative Works of,
|
||||||
|
publicly display, publicly perform, sublicense, and distribute the
|
||||||
|
Work and such Derivative Works in Source or Object form.
|
||||||
|
|
||||||
|
3. Grant of Patent License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
(except as stated in this section) patent license to make, have made,
|
||||||
|
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||||
|
where such license applies only to those patent claims licensable
|
||||||
|
by such Contributor that are necessarily infringed by their
|
||||||
|
Contribution(s) alone or by combination of their Contribution(s)
|
||||||
|
with the Work to which such Contribution(s) was submitted. If You
|
||||||
|
institute patent litigation against any entity (including a
|
||||||
|
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||||
|
or a Contribution incorporated within the Work constitutes direct
|
||||||
|
or contributory patent infringement, then any patent licenses
|
||||||
|
granted to You under this License for that Work shall terminate
|
||||||
|
as of the date such litigation is filed.
|
||||||
|
|
||||||
|
4. Redistribution. You may reproduce and distribute copies of the
|
||||||
|
Work or Derivative Works thereof in any medium, with or without
|
||||||
|
modifications, and in Source or Object form, provided that You
|
||||||
|
meet the following conditions:
|
||||||
|
|
||||||
|
(a) You must give any other recipients of the Work or
|
||||||
|
Derivative Works a copy of this License; and
|
||||||
|
|
||||||
|
(b) You must cause any modified files to carry prominent notices
|
||||||
|
stating that You changed the files; and
|
||||||
|
|
||||||
|
(c) You must retain, in the Source form of any Derivative Works
|
||||||
|
that You distribute, all copyright, patent, trademark, and
|
||||||
|
attribution notices from the Source form of the Work,
|
||||||
|
excluding those notices that do not pertain to any part of
|
||||||
|
the Derivative Works; and
|
||||||
|
|
||||||
|
(d) If the Work includes a "NOTICE" text file as part of its
|
||||||
|
distribution, then any Derivative Works that You distribute must
|
||||||
|
include a readable copy of the attribution notices contained
|
||||||
|
within such NOTICE file, excluding those notices that do not
|
||||||
|
pertain to any part of the Derivative Works, in at least one
|
||||||
|
of the following places: within a NOTICE text file distributed
|
||||||
|
as part of the Derivative Works; within the Source form or
|
||||||
|
documentation, if provided along with the Derivative Works; or,
|
||||||
|
within a display generated by the Derivative Works, if and
|
||||||
|
wherever such third-party notices normally appear. The contents
|
||||||
|
of the NOTICE file are for informational purposes only and
|
||||||
|
do not modify the License. You may add Your own attribution
|
||||||
|
notices within Derivative Works that You distribute, alongside
|
||||||
|
or as an addendum to the NOTICE text from the Work, provided
|
||||||
|
that such additional attribution notices cannot be construed
|
||||||
|
as modifying the License.
|
||||||
|
|
||||||
|
You may add Your own copyright statement to Your modifications and
|
||||||
|
may provide additional or different license terms and conditions
|
||||||
|
for use, reproduction, or distribution of Your modifications, or
|
||||||
|
for any such Derivative Works as a whole, provided Your use,
|
||||||
|
reproduction, and distribution of the Work otherwise complies with
|
||||||
|
the conditions stated in this License.
|
||||||
|
|
||||||
|
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||||
|
any Contribution intentionally submitted for inclusion in the Work
|
||||||
|
by You to the Licensor shall be under the terms and conditions of
|
||||||
|
this License, without any additional terms or conditions.
|
||||||
|
Notwithstanding the above, nothing herein shall supersede or modify
|
||||||
|
the terms of any separate license agreement you may have executed
|
||||||
|
with Licensor regarding such Contributions.
|
||||||
|
|
||||||
|
6. Trademarks. This License does not grant permission to use the trade
|
||||||
|
names, trademarks, service marks, or product names of the Licensor,
|
||||||
|
except as required for reasonable and customary use in describing the
|
||||||
|
origin of the Work and reproducing the content of the NOTICE file.
|
||||||
|
|
||||||
|
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||||
|
agreed to in writing, Licensor provides the Work (and each
|
||||||
|
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||||
|
implied, including, without limitation, any warranties or conditions
|
||||||
|
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||||
|
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||||
|
appropriateness of using or redistributing the Work and assume any
|
||||||
|
risks associated with Your exercise of permissions under this License.
|
||||||
|
|
||||||
|
8. Limitation of Liability. In no event and under no legal theory,
|
||||||
|
whether in tort (including negligence), contract, or otherwise,
|
||||||
|
unless required by applicable law (such as deliberate and grossly
|
||||||
|
negligent acts) or agreed to in writing, shall any Contributor be
|
||||||
|
liable to You for damages, including any direct, indirect, special,
|
||||||
|
incidental, or consequential damages of any character arising as a
|
||||||
|
result of this License or out of the use or inability to use the
|
||||||
|
Work (including but not limited to damages for loss of goodwill,
|
||||||
|
work stoppage, computer failure or malfunction, or any and all
|
||||||
|
other commercial damages or losses), even if such Contributor
|
||||||
|
has been advised of the possibility of such damages.
|
||||||
|
|
||||||
|
9. Accepting Warranty or Additional Liability. While redistributing
|
||||||
|
the Work or Derivative Works thereof, You may choose to offer,
|
||||||
|
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||||
|
or other liability obligations and/or rights consistent with this
|
||||||
|
License. However, in accepting such obligations, You may act only
|
||||||
|
on Your own behalf and on Your sole responsibility, not on behalf
|
||||||
|
of any other Contributor, and only if You agree to indemnify,
|
||||||
|
defend, and hold each Contributor harmless for any liability
|
||||||
|
incurred by, or claims asserted against, such Contributor by reason
|
||||||
|
of your accepting any such warranty or additional liability.
|
||||||
|
|
||||||
|
END OF TERMS AND CONDITIONS
|
||||||
|
|
||||||
|
APPENDIX: How to apply the Apache License to your work.
|
||||||
|
|
||||||
|
To apply the Apache License to your work, attach the following
|
||||||
|
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||||
|
replaced with your own identifying information. (Don't include
|
||||||
|
the brackets!) The text should be enclosed in the appropriate
|
||||||
|
comment syntax for the file format. We also recommend that a
|
||||||
|
file or class name and description of purpose be included on the
|
||||||
|
same "printed page" as the copyright notice for easier
|
||||||
|
identification within third-party archives.
|
||||||
|
|
||||||
|
Copyright [yyyy] [name of copyright owner]
|
||||||
|
|
||||||
|
Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
you may not use this file except in compliance with the License.
|
||||||
|
You may obtain a copy of the License at
|
||||||
|
|
||||||
|
http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
Unless required by applicable law or agreed to in writing, software
|
||||||
|
distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
See the License for the specific language governing permissions and
|
||||||
|
limitations under the License.
|
||||||
@ -0,0 +1,76 @@
|
|||||||
|
{
|
||||||
|
"validate#dataset#cache_rate": 0,
|
||||||
|
"validate#postprocessing": {
|
||||||
|
"_target_": "Compose",
|
||||||
|
"transforms": [
|
||||||
|
{
|
||||||
|
"_target_": "Activationsd",
|
||||||
|
"keys": "pred",
|
||||||
|
"softmax": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "Invertd",
|
||||||
|
"keys": [
|
||||||
|
"pred",
|
||||||
|
"label"
|
||||||
|
],
|
||||||
|
"transform": "@validate#preprocessing",
|
||||||
|
"orig_keys": "image",
|
||||||
|
"nearest_interp": [
|
||||||
|
false,
|
||||||
|
true
|
||||||
|
],
|
||||||
|
"to_tensor": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "AsDiscreted",
|
||||||
|
"keys": [
|
||||||
|
"pred",
|
||||||
|
"label"
|
||||||
|
],
|
||||||
|
"argmax": [
|
||||||
|
true,
|
||||||
|
false
|
||||||
|
],
|
||||||
|
"to_onehot": 2
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "SaveImaged",
|
||||||
|
"_disabled_": true,
|
||||||
|
"keys": "pred",
|
||||||
|
"output_dir": "@output_dir",
|
||||||
|
"resample": false,
|
||||||
|
"squeeze_end_dims": true
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"validate#handlers": [
|
||||||
|
{
|
||||||
|
"_target_": "CheckpointLoader",
|
||||||
|
"load_path": "$@ckpt_dir + '/model.pt'",
|
||||||
|
"load_dict": {
|
||||||
|
"model": "@network"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "StatsHandler",
|
||||||
|
"iteration_log": false
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "MetricsSaver",
|
||||||
|
"save_dir": "@output_dir",
|
||||||
|
"metrics": [
|
||||||
|
"val_mean_dice",
|
||||||
|
"val_acc"
|
||||||
|
],
|
||||||
|
"metric_details": [
|
||||||
|
"val_mean_dice"
|
||||||
|
],
|
||||||
|
"batch_transform": "$lambda x: [xx['image'].meta for xx in x]",
|
||||||
|
"summary_ops": "*"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"run": [
|
||||||
|
"$@validate#evaluator.run()"
|
||||||
|
]
|
||||||
|
}
|
||||||
165
ai-medical/models/spleen_ct_segmentation/configs/inference.json
Normal file
165
ai-medical/models/spleen_ct_segmentation/configs/inference.json
Normal file
@ -0,0 +1,165 @@
|
|||||||
|
{
|
||||||
|
"imports": [
|
||||||
|
"$import glob",
|
||||||
|
"$import numpy",
|
||||||
|
"$import os"
|
||||||
|
],
|
||||||
|
"bundle_root": ".",
|
||||||
|
"image_key": "image",
|
||||||
|
"output_dir": "$@bundle_root + '/eval'",
|
||||||
|
"output_ext": ".nii.gz",
|
||||||
|
"output_dtype": "$numpy.float32",
|
||||||
|
"output_postfix": "trans",
|
||||||
|
"separate_folder": true,
|
||||||
|
"load_pretrain": true,
|
||||||
|
"dataset_dir": "/workspace/data/Task09_Spleen",
|
||||||
|
"datalist": "$list(sorted(glob.glob(@dataset_dir + '/imagesTs/*.nii.gz')))",
|
||||||
|
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
||||||
|
"network_def": {
|
||||||
|
"_target_": "UNet",
|
||||||
|
"spatial_dims": 3,
|
||||||
|
"in_channels": 1,
|
||||||
|
"out_channels": 2,
|
||||||
|
"channels": [
|
||||||
|
16,
|
||||||
|
32,
|
||||||
|
64,
|
||||||
|
128,
|
||||||
|
256
|
||||||
|
],
|
||||||
|
"strides": [
|
||||||
|
2,
|
||||||
|
2,
|
||||||
|
2,
|
||||||
|
2
|
||||||
|
],
|
||||||
|
"num_res_units": 2,
|
||||||
|
"norm": "batch"
|
||||||
|
},
|
||||||
|
"network": "$@network_def.to(@device)",
|
||||||
|
"preprocessing": {
|
||||||
|
"_target_": "Compose",
|
||||||
|
"transforms": [
|
||||||
|
{
|
||||||
|
"_target_": "LoadImaged",
|
||||||
|
"keys": "@image_key"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "EnsureChannelFirstd",
|
||||||
|
"keys": "@image_key"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "Orientationd",
|
||||||
|
"keys": "@image_key",
|
||||||
|
"axcodes": "RAS"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "Spacingd",
|
||||||
|
"keys": "@image_key",
|
||||||
|
"pixdim": [
|
||||||
|
1.5,
|
||||||
|
1.5,
|
||||||
|
2.0
|
||||||
|
],
|
||||||
|
"mode": "bilinear"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "ScaleIntensityRanged",
|
||||||
|
"keys": "@image_key",
|
||||||
|
"a_min": -57,
|
||||||
|
"a_max": 164,
|
||||||
|
"b_min": 0,
|
||||||
|
"b_max": 1,
|
||||||
|
"clip": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "EnsureTyped",
|
||||||
|
"keys": "@image_key"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"dataset": {
|
||||||
|
"_target_": "Dataset",
|
||||||
|
"data": "$[{'image': i} for i in @datalist]",
|
||||||
|
"transform": "@preprocessing"
|
||||||
|
},
|
||||||
|
"dataloader": {
|
||||||
|
"_target_": "DataLoader",
|
||||||
|
"dataset": "@dataset",
|
||||||
|
"batch_size": 1,
|
||||||
|
"shuffle": false,
|
||||||
|
"num_workers": 4
|
||||||
|
},
|
||||||
|
"inferer": {
|
||||||
|
"_target_": "SlidingWindowInferer",
|
||||||
|
"roi_size": [
|
||||||
|
96,
|
||||||
|
96,
|
||||||
|
96
|
||||||
|
],
|
||||||
|
"sw_batch_size": 4,
|
||||||
|
"overlap": 0.5
|
||||||
|
},
|
||||||
|
"postprocessing": {
|
||||||
|
"_target_": "Compose",
|
||||||
|
"transforms": [
|
||||||
|
{
|
||||||
|
"_target_": "Activationsd",
|
||||||
|
"keys": "pred",
|
||||||
|
"softmax": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "Invertd",
|
||||||
|
"keys": "pred",
|
||||||
|
"transform": "@preprocessing",
|
||||||
|
"orig_keys": "@image_key",
|
||||||
|
"nearest_interp": false,
|
||||||
|
"to_tensor": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "AsDiscreted",
|
||||||
|
"keys": "pred",
|
||||||
|
"argmax": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "SaveImaged",
|
||||||
|
"keys": "pred",
|
||||||
|
"output_dir": "@output_dir",
|
||||||
|
"output_ext": "@output_ext",
|
||||||
|
"output_dtype": "@output_dtype",
|
||||||
|
"output_postfix": "@output_postfix",
|
||||||
|
"separate_folder": "@separate_folder"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"handlers": [
|
||||||
|
{
|
||||||
|
"_target_": "StatsHandler",
|
||||||
|
"iteration_log": false
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"evaluator": {
|
||||||
|
"_target_": "SupervisedEvaluator",
|
||||||
|
"device": "@device",
|
||||||
|
"val_data_loader": "@dataloader",
|
||||||
|
"network": "@network",
|
||||||
|
"inferer": "@inferer",
|
||||||
|
"postprocessing": "@postprocessing",
|
||||||
|
"val_handlers": "@handlers",
|
||||||
|
"amp": true
|
||||||
|
},
|
||||||
|
"checkpointloader": {
|
||||||
|
"_target_": "CheckpointLoader",
|
||||||
|
"load_path": "$@bundle_root + '/models/model.pt'",
|
||||||
|
"load_dict": {
|
||||||
|
"model": "@network"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"initialize": [
|
||||||
|
"$monai.utils.set_determinism(seed=123)",
|
||||||
|
"$@checkpointloader(@evaluator) if @load_pretrain else None"
|
||||||
|
],
|
||||||
|
"run": [
|
||||||
|
"$@evaluator.run()"
|
||||||
|
]
|
||||||
|
}
|
||||||
@ -0,0 +1,12 @@
|
|||||||
|
{
|
||||||
|
"imports": [
|
||||||
|
"$import glob",
|
||||||
|
"$import os",
|
||||||
|
"$import torch_tensorrt"
|
||||||
|
],
|
||||||
|
"network_def": "$torch.jit.load(@bundle_root + '/models/model_trt.ts')",
|
||||||
|
"evaluator#amp": false,
|
||||||
|
"initialize": [
|
||||||
|
"$monai.utils.set_determinism(seed=123)"
|
||||||
|
]
|
||||||
|
}
|
||||||
@ -0,0 +1,21 @@
|
|||||||
|
[loggers]
|
||||||
|
keys=root
|
||||||
|
|
||||||
|
[handlers]
|
||||||
|
keys=consoleHandler
|
||||||
|
|
||||||
|
[formatters]
|
||||||
|
keys=fullFormatter
|
||||||
|
|
||||||
|
[logger_root]
|
||||||
|
level=INFO
|
||||||
|
handlers=consoleHandler
|
||||||
|
|
||||||
|
[handler_consoleHandler]
|
||||||
|
class=StreamHandler
|
||||||
|
level=INFO
|
||||||
|
formatter=fullFormatter
|
||||||
|
args=(sys.stdout,)
|
||||||
|
|
||||||
|
[formatter_fullFormatter]
|
||||||
|
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
|
||||||
115
ai-medical/models/spleen_ct_segmentation/configs/metadata.json
Normal file
115
ai-medical/models/spleen_ct_segmentation/configs/metadata.json
Normal file
@ -0,0 +1,115 @@
|
|||||||
|
{
|
||||||
|
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20240725.json",
|
||||||
|
"version": "0.6.1",
|
||||||
|
"changelog": {
|
||||||
|
"0.6.1": "enhance metadata with improved descriptions",
|
||||||
|
"0.6.0": "update to huggingface hosting",
|
||||||
|
"0.5.9": "use monai 1.4 and update large files",
|
||||||
|
"0.5.8": "update to use monai 1.3.2",
|
||||||
|
"0.5.7": "update to use monai 1.3.1",
|
||||||
|
"0.5.6": "add load_pretrain flag for infer",
|
||||||
|
"0.5.5": "add checkpoint loader for infer",
|
||||||
|
"0.5.4": "update to use monai 1.3.0",
|
||||||
|
"0.5.3": "fix the wrong GPU index issue of multi-node",
|
||||||
|
"0.5.2": "remove error dollar symbol in readme",
|
||||||
|
"0.5.1": "add RAM warning",
|
||||||
|
"0.5.0": "update the README file with the ONNX-TensorRT conversion",
|
||||||
|
"0.4.9": "update TensorRT descriptions",
|
||||||
|
"0.4.8": "update deterministic training results",
|
||||||
|
"0.4.7": "update the TensorRT part in the README file",
|
||||||
|
"0.4.6": "fix mgpu finalize issue",
|
||||||
|
"0.4.5": "enable deterministic training",
|
||||||
|
"0.4.4": "add the command of executing inference with TensorRT models",
|
||||||
|
"0.4.3": "fix figure and weights inconsistent error",
|
||||||
|
"0.4.2": "use torch 1.13.1",
|
||||||
|
"0.4.1": "update the readme file with TensorRT convert",
|
||||||
|
"0.4.0": "fix multi-gpu train config typo",
|
||||||
|
"0.3.9": "adapt to BundleWorkflow interface",
|
||||||
|
"0.3.8": "add name tag",
|
||||||
|
"0.3.7": "restructure readme to match updated template",
|
||||||
|
"0.3.6": "enhance readme with details of model training",
|
||||||
|
"0.3.5": "update to use monai 1.0.1",
|
||||||
|
"0.3.4": "enhance readme on commands example",
|
||||||
|
"0.3.3": "fix license Copyright error",
|
||||||
|
"0.3.2": "improve multi-gpu logging",
|
||||||
|
"0.3.1": "add multi-gpu evaluation config",
|
||||||
|
"0.3.0": "update license files",
|
||||||
|
"0.2.0": "unify naming",
|
||||||
|
"0.1.1": "disable image saving during evaluation",
|
||||||
|
"0.1.0": "complete the model package",
|
||||||
|
"0.0.1": "initialize the model package structure"
|
||||||
|
},
|
||||||
|
"monai_version": "1.4.0",
|
||||||
|
"pytorch_version": "2.4.0",
|
||||||
|
"numpy_version": "1.24.4",
|
||||||
|
"required_packages_version": {
|
||||||
|
"nibabel": "5.2.1",
|
||||||
|
"pytorch-ignite": "0.4.11",
|
||||||
|
"tensorboard": "2.17.0"
|
||||||
|
},
|
||||||
|
"supported_apps": {},
|
||||||
|
"name": "Spleen CT Segmentation",
|
||||||
|
"task": "Automated Spleen Segmentation in CT Images",
|
||||||
|
"description": "A 3D segmentation model for spleen delineation in CT images. The model processes 96x96x96 pixel patches and provides segmentation masks for spleen tissue. Trained on the Medical Segmentation Decathlon dataset.",
|
||||||
|
"authors": "MONAI team",
|
||||||
|
"copyright": "Copyright (c) MONAI Consortium",
|
||||||
|
"data_source": "Task09_Spleen.tar from http://medicaldecathlon.com/",
|
||||||
|
"data_type": "nibabel",
|
||||||
|
"image_classes": "single channel data, intensity scaled to [0, 1]",
|
||||||
|
"label_classes": "single channel data, 1 is spleen, 0 is everything else",
|
||||||
|
"pred_classes": "2 channels OneHot data, channel 1 is spleen, channel 0 is background",
|
||||||
|
"eval_metrics": {
|
||||||
|
"mean_dice": 0.961
|
||||||
|
},
|
||||||
|
"intended_use": "This is an example, not to be used for diagnostic purposes",
|
||||||
|
"references": [
|
||||||
|
"Xia, Yingda, et al. '3D Semi-Supervised Learning with Uncertainty-Aware Multi-View Co-Training. arXiv preprint arXiv:1811.12506 (2018). https://arxiv.org/abs/1811.12506.",
|
||||||
|
"Kerfoot E., Clough J., Oksuz I., Lee J., King A.P., Schnabel J.A. (2019) Left-Ventricle Quantification Using Residual U-Net. In: Pop M. et al. (eds) Statistical Atlases and Computational Models of the Heart. Atrial Segmentation and LV Quantification Challenges. STACOM 2018. Lecture Notes in Computer Science, vol 11395. Springer, Cham. https://doi.org/10.1007/978-3-030-12029-0_40"
|
||||||
|
],
|
||||||
|
"network_data_format": {
|
||||||
|
"inputs": {
|
||||||
|
"image": {
|
||||||
|
"type": "image",
|
||||||
|
"format": "hounsfield",
|
||||||
|
"modality": "CT",
|
||||||
|
"num_channels": 1,
|
||||||
|
"spatial_shape": [
|
||||||
|
96,
|
||||||
|
96,
|
||||||
|
96
|
||||||
|
],
|
||||||
|
"dtype": "float32",
|
||||||
|
"value_range": [
|
||||||
|
0,
|
||||||
|
1
|
||||||
|
],
|
||||||
|
"is_patch_data": true,
|
||||||
|
"channel_def": {
|
||||||
|
"0": "image"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"outputs": {
|
||||||
|
"pred": {
|
||||||
|
"type": "image",
|
||||||
|
"format": "segmentation",
|
||||||
|
"num_channels": 2,
|
||||||
|
"spatial_shape": [
|
||||||
|
96,
|
||||||
|
96,
|
||||||
|
96
|
||||||
|
],
|
||||||
|
"dtype": "float32",
|
||||||
|
"value_range": [
|
||||||
|
0,
|
||||||
|
1
|
||||||
|
],
|
||||||
|
"is_patch_data": true,
|
||||||
|
"channel_def": {
|
||||||
|
"0": "background",
|
||||||
|
"1": "spleen"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
@ -0,0 +1,31 @@
|
|||||||
|
{
|
||||||
|
"device": "$torch.device('cuda:' + os.environ['LOCAL_RANK'])",
|
||||||
|
"network": {
|
||||||
|
"_target_": "torch.nn.parallel.DistributedDataParallel",
|
||||||
|
"module": "$@network_def.to(@device)",
|
||||||
|
"device_ids": [
|
||||||
|
"@device"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"validate#sampler": {
|
||||||
|
"_target_": "DistributedSampler",
|
||||||
|
"dataset": "@validate#dataset",
|
||||||
|
"even_divisible": false,
|
||||||
|
"shuffle": false
|
||||||
|
},
|
||||||
|
"validate#dataloader#sampler": "@validate#sampler",
|
||||||
|
"validate#handlers#1#_disabled_": "$dist.get_rank() > 0",
|
||||||
|
"initialize": [
|
||||||
|
"$import torch.distributed as dist",
|
||||||
|
"$dist.is_initialized() or dist.init_process_group(backend='nccl')",
|
||||||
|
"$torch.cuda.set_device(@device)",
|
||||||
|
"$import logging",
|
||||||
|
"$@validate#evaluator.logger.setLevel(logging.WARNING if dist.get_rank() > 0 else logging.INFO)"
|
||||||
|
],
|
||||||
|
"run": [
|
||||||
|
"$@validate#evaluator.run()"
|
||||||
|
],
|
||||||
|
"finalize": [
|
||||||
|
"$dist.is_initialized() and dist.destroy_process_group()"
|
||||||
|
]
|
||||||
|
}
|
||||||
@ -0,0 +1,42 @@
|
|||||||
|
{
|
||||||
|
"device": "$torch.device('cuda:' + os.environ['LOCAL_RANK'])",
|
||||||
|
"network": {
|
||||||
|
"_target_": "torch.nn.parallel.DistributedDataParallel",
|
||||||
|
"module": "$@network_def.to(@device)",
|
||||||
|
"device_ids": [
|
||||||
|
"@device"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"train#sampler": {
|
||||||
|
"_target_": "DistributedSampler",
|
||||||
|
"dataset": "@train#dataset",
|
||||||
|
"even_divisible": true,
|
||||||
|
"shuffle": true
|
||||||
|
},
|
||||||
|
"train#dataloader#sampler": "@train#sampler",
|
||||||
|
"train#dataloader#shuffle": false,
|
||||||
|
"train#trainer#train_handlers": "$@train#handlers[: -2 if dist.get_rank() > 0 else None]",
|
||||||
|
"validate#sampler": {
|
||||||
|
"_target_": "DistributedSampler",
|
||||||
|
"dataset": "@validate#dataset",
|
||||||
|
"even_divisible": false,
|
||||||
|
"shuffle": false
|
||||||
|
},
|
||||||
|
"validate#dataloader#sampler": "@validate#sampler",
|
||||||
|
"validate#evaluator#val_handlers": "$None if dist.get_rank() > 0 else @validate#handlers",
|
||||||
|
"initialize": [
|
||||||
|
"$import torch.distributed as dist",
|
||||||
|
"$dist.is_initialized() or dist.init_process_group(backend='nccl')",
|
||||||
|
"$torch.cuda.set_device(@device)",
|
||||||
|
"$monai.utils.set_determinism(seed=123)",
|
||||||
|
"$import logging",
|
||||||
|
"$@train#trainer.logger.setLevel(logging.WARNING if dist.get_rank() > 0 else logging.INFO)",
|
||||||
|
"$@validate#evaluator.logger.setLevel(logging.WARNING if dist.get_rank() > 0 else logging.INFO)"
|
||||||
|
],
|
||||||
|
"run": [
|
||||||
|
"$@train#trainer.run()"
|
||||||
|
],
|
||||||
|
"finalize": [
|
||||||
|
"$dist.is_initialized() and dist.destroy_process_group()"
|
||||||
|
]
|
||||||
|
}
|
||||||
307
ai-medical/models/spleen_ct_segmentation/configs/train.json
Normal file
307
ai-medical/models/spleen_ct_segmentation/configs/train.json
Normal file
@ -0,0 +1,307 @@
|
|||||||
|
{
|
||||||
|
"imports": [
|
||||||
|
"$import glob",
|
||||||
|
"$import os",
|
||||||
|
"$import ignite"
|
||||||
|
],
|
||||||
|
"bundle_root": ".",
|
||||||
|
"ckpt_dir": "$@bundle_root + '/models'",
|
||||||
|
"output_dir": "$@bundle_root + '/eval'",
|
||||||
|
"dataset_dir": "/workspace/data/Task09_Spleen",
|
||||||
|
"images": "$list(sorted(glob.glob(@dataset_dir + '/imagesTr/*.nii.gz')))",
|
||||||
|
"labels": "$list(sorted(glob.glob(@dataset_dir + '/labelsTr/*.nii.gz')))",
|
||||||
|
"val_interval": 1,
|
||||||
|
"epochs": 800,
|
||||||
|
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
||||||
|
"network_def": {
|
||||||
|
"_target_": "UNet",
|
||||||
|
"spatial_dims": 3,
|
||||||
|
"in_channels": 1,
|
||||||
|
"out_channels": 2,
|
||||||
|
"channels": [
|
||||||
|
16,
|
||||||
|
32,
|
||||||
|
64,
|
||||||
|
128,
|
||||||
|
256
|
||||||
|
],
|
||||||
|
"strides": [
|
||||||
|
2,
|
||||||
|
2,
|
||||||
|
2,
|
||||||
|
2
|
||||||
|
],
|
||||||
|
"num_res_units": 2,
|
||||||
|
"norm": "batch"
|
||||||
|
},
|
||||||
|
"network": "$@network_def.to(@device)",
|
||||||
|
"loss": {
|
||||||
|
"_target_": "DiceCELoss",
|
||||||
|
"include_background": true,
|
||||||
|
"to_onehot_y": true,
|
||||||
|
"softmax": true,
|
||||||
|
"squared_pred": true,
|
||||||
|
"batch": true,
|
||||||
|
"smooth_nr": 1e-05,
|
||||||
|
"smooth_dr": 1e-05,
|
||||||
|
"lambda_dice": 0.5,
|
||||||
|
"lambda_ce": 0.5
|
||||||
|
},
|
||||||
|
"optimizer": {
|
||||||
|
"_target_": "Novograd",
|
||||||
|
"params": "$@network.parameters()",
|
||||||
|
"lr": 0.002
|
||||||
|
},
|
||||||
|
"lr_scheduler": {
|
||||||
|
"_target_": "torch.optim.lr_scheduler.StepLR",
|
||||||
|
"optimizer": "@optimizer",
|
||||||
|
"step_size": 5000,
|
||||||
|
"gamma": 0.1
|
||||||
|
},
|
||||||
|
"train": {
|
||||||
|
"deterministic_transforms": [
|
||||||
|
{
|
||||||
|
"_target_": "LoadImaged",
|
||||||
|
"keys": [
|
||||||
|
"image",
|
||||||
|
"label"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "EnsureChannelFirstd",
|
||||||
|
"keys": [
|
||||||
|
"image",
|
||||||
|
"label"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "Orientationd",
|
||||||
|
"keys": [
|
||||||
|
"image",
|
||||||
|
"label"
|
||||||
|
],
|
||||||
|
"axcodes": "RAS"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "Spacingd",
|
||||||
|
"keys": [
|
||||||
|
"image",
|
||||||
|
"label"
|
||||||
|
],
|
||||||
|
"pixdim": [
|
||||||
|
1.5,
|
||||||
|
1.5,
|
||||||
|
2.0
|
||||||
|
],
|
||||||
|
"mode": [
|
||||||
|
"bilinear",
|
||||||
|
"nearest"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "ScaleIntensityRanged",
|
||||||
|
"keys": "image",
|
||||||
|
"a_min": -57,
|
||||||
|
"a_max": 164,
|
||||||
|
"b_min": 0,
|
||||||
|
"b_max": 1,
|
||||||
|
"clip": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "EnsureTyped",
|
||||||
|
"keys": [
|
||||||
|
"image",
|
||||||
|
"label"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"random_transforms": [
|
||||||
|
{
|
||||||
|
"_target_": "RandCropByPosNegLabeld",
|
||||||
|
"keys": [
|
||||||
|
"image",
|
||||||
|
"label"
|
||||||
|
],
|
||||||
|
"label_key": "label",
|
||||||
|
"spatial_size": [
|
||||||
|
96,
|
||||||
|
96,
|
||||||
|
96
|
||||||
|
],
|
||||||
|
"pos": 1,
|
||||||
|
"neg": 1,
|
||||||
|
"num_samples": 4,
|
||||||
|
"image_key": "image",
|
||||||
|
"image_threshold": 0
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"preprocessing": {
|
||||||
|
"_target_": "Compose",
|
||||||
|
"transforms": "$@train#deterministic_transforms + @train#random_transforms"
|
||||||
|
},
|
||||||
|
"dataset": {
|
||||||
|
"_target_": "CacheDataset",
|
||||||
|
"data": "$[{'image': i, 'label': l} for i, l in zip(@images[:-9], @labels[:-9])]",
|
||||||
|
"transform": "@train#preprocessing",
|
||||||
|
"cache_rate": 1.0,
|
||||||
|
"num_workers": 4
|
||||||
|
},
|
||||||
|
"dataloader": {
|
||||||
|
"_target_": "DataLoader",
|
||||||
|
"dataset": "@train#dataset",
|
||||||
|
"batch_size": 2,
|
||||||
|
"shuffle": true,
|
||||||
|
"num_workers": 4
|
||||||
|
},
|
||||||
|
"inferer": {
|
||||||
|
"_target_": "SimpleInferer"
|
||||||
|
},
|
||||||
|
"postprocessing": {
|
||||||
|
"_target_": "Compose",
|
||||||
|
"transforms": [
|
||||||
|
{
|
||||||
|
"_target_": "Activationsd",
|
||||||
|
"keys": "pred",
|
||||||
|
"softmax": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "AsDiscreted",
|
||||||
|
"keys": [
|
||||||
|
"pred",
|
||||||
|
"label"
|
||||||
|
],
|
||||||
|
"argmax": [
|
||||||
|
true,
|
||||||
|
false
|
||||||
|
],
|
||||||
|
"to_onehot": 2
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"handlers": [
|
||||||
|
{
|
||||||
|
"_target_": "LrScheduleHandler",
|
||||||
|
"lr_scheduler": "@lr_scheduler",
|
||||||
|
"print_lr": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "ValidationHandler",
|
||||||
|
"validator": "@validate#evaluator",
|
||||||
|
"epoch_level": true,
|
||||||
|
"interval": "@val_interval"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "StatsHandler",
|
||||||
|
"tag_name": "train_loss",
|
||||||
|
"output_transform": "$monai.handlers.from_engine(['loss'], first=True)"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "TensorBoardStatsHandler",
|
||||||
|
"log_dir": "@output_dir",
|
||||||
|
"tag_name": "train_loss",
|
||||||
|
"output_transform": "$monai.handlers.from_engine(['loss'], first=True)"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"key_metric": {
|
||||||
|
"train_accuracy": {
|
||||||
|
"_target_": "ignite.metrics.Accuracy",
|
||||||
|
"output_transform": "$monai.handlers.from_engine(['pred', 'label'])"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"trainer": {
|
||||||
|
"_target_": "SupervisedTrainer",
|
||||||
|
"max_epochs": "@epochs",
|
||||||
|
"device": "@device",
|
||||||
|
"train_data_loader": "@train#dataloader",
|
||||||
|
"network": "@network",
|
||||||
|
"loss_function": "@loss",
|
||||||
|
"optimizer": "@optimizer",
|
||||||
|
"inferer": "@train#inferer",
|
||||||
|
"postprocessing": "@train#postprocessing",
|
||||||
|
"key_train_metric": "@train#key_metric",
|
||||||
|
"train_handlers": "@train#handlers",
|
||||||
|
"amp": true
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"validate": {
|
||||||
|
"preprocessing": {
|
||||||
|
"_target_": "Compose",
|
||||||
|
"transforms": "%train#deterministic_transforms"
|
||||||
|
},
|
||||||
|
"dataset": {
|
||||||
|
"_target_": "CacheDataset",
|
||||||
|
"data": "$[{'image': i, 'label': l} for i, l in zip(@images[-9:], @labels[-9:])]",
|
||||||
|
"transform": "@validate#preprocessing",
|
||||||
|
"cache_rate": 1.0
|
||||||
|
},
|
||||||
|
"dataloader": {
|
||||||
|
"_target_": "DataLoader",
|
||||||
|
"dataset": "@validate#dataset",
|
||||||
|
"batch_size": 1,
|
||||||
|
"shuffle": false,
|
||||||
|
"num_workers": 4
|
||||||
|
},
|
||||||
|
"inferer": {
|
||||||
|
"_target_": "SlidingWindowInferer",
|
||||||
|
"roi_size": [
|
||||||
|
96,
|
||||||
|
96,
|
||||||
|
96
|
||||||
|
],
|
||||||
|
"sw_batch_size": 4,
|
||||||
|
"overlap": 0.5
|
||||||
|
},
|
||||||
|
"postprocessing": "%train#postprocessing",
|
||||||
|
"handlers": [
|
||||||
|
{
|
||||||
|
"_target_": "StatsHandler",
|
||||||
|
"iteration_log": false
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "TensorBoardStatsHandler",
|
||||||
|
"log_dir": "@output_dir",
|
||||||
|
"iteration_log": false
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"_target_": "CheckpointSaver",
|
||||||
|
"save_dir": "@ckpt_dir",
|
||||||
|
"save_dict": {
|
||||||
|
"model": "@network"
|
||||||
|
},
|
||||||
|
"save_key_metric": true,
|
||||||
|
"key_metric_filename": "model.pt"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"key_metric": {
|
||||||
|
"val_mean_dice": {
|
||||||
|
"_target_": "MeanDice",
|
||||||
|
"include_background": false,
|
||||||
|
"output_transform": "$monai.handlers.from_engine(['pred', 'label'])"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"additional_metrics": {
|
||||||
|
"val_accuracy": {
|
||||||
|
"_target_": "ignite.metrics.Accuracy",
|
||||||
|
"output_transform": "$monai.handlers.from_engine(['pred', 'label'])"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"evaluator": {
|
||||||
|
"_target_": "SupervisedEvaluator",
|
||||||
|
"device": "@device",
|
||||||
|
"val_data_loader": "@validate#dataloader",
|
||||||
|
"network": "@network",
|
||||||
|
"inferer": "@validate#inferer",
|
||||||
|
"postprocessing": "@validate#postprocessing",
|
||||||
|
"key_val_metric": "@validate#key_metric",
|
||||||
|
"additional_metrics": "@validate#additional_metrics",
|
||||||
|
"val_handlers": "@validate#handlers",
|
||||||
|
"amp": true
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"initialize": [
|
||||||
|
"$monai.utils.set_determinism(seed=123)"
|
||||||
|
],
|
||||||
|
"run": [
|
||||||
|
"$@train#trainer.run()"
|
||||||
|
]
|
||||||
|
}
|
||||||
152
ai-medical/models/spleen_ct_segmentation/docs/README.md
Normal file
152
ai-medical/models/spleen_ct_segmentation/docs/README.md
Normal file
@ -0,0 +1,152 @@
|
|||||||
|
# Model Overview
|
||||||
|
A pre-trained model for volumetric (3D) segmentation of the spleen from CT images.
|
||||||
|
|
||||||
|
This model is trained using the runner-up [1] awarded pipeline of the "Medical Segmentation Decathlon Challenge 2018" using the UNet architecture [2] with 32 training images and 9 validation images.
|
||||||
|
|
||||||
|
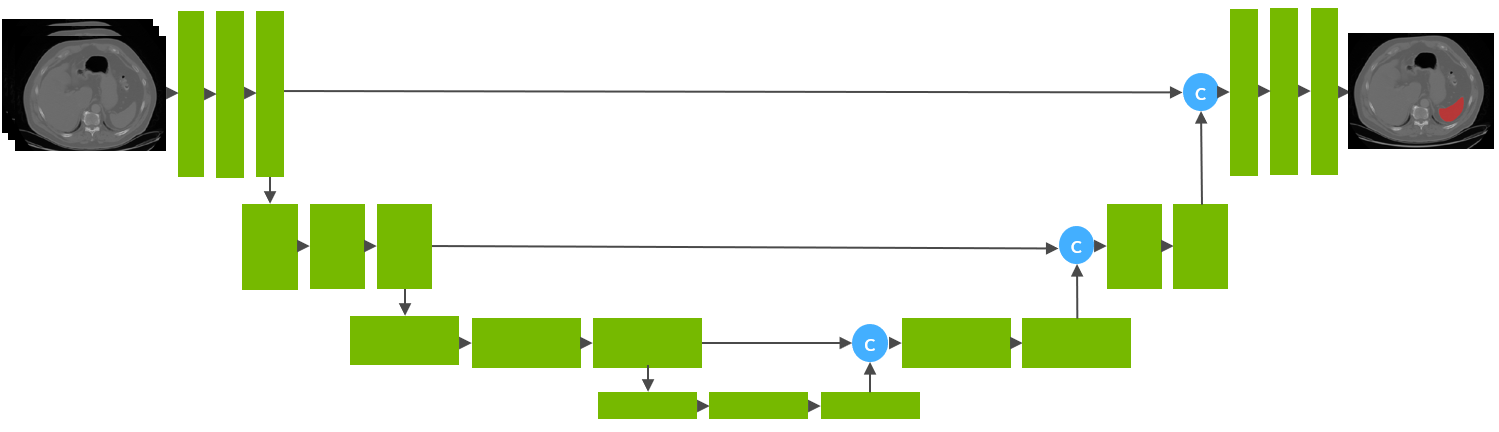
|
||||||
|
|
||||||
|
## Data
|
||||||
|
The training dataset is the Spleen Task from the Medical Segmentation Decathalon. Users can find more details on the datasets at http://medicaldecathlon.com/.
|
||||||
|
|
||||||
|
- Target: Spleen
|
||||||
|
- Modality: CT
|
||||||
|
- Size: 61 3D volumes (41 Training + 20 Testing)
|
||||||
|
- Source: Memorial Sloan Kettering Cancer Center
|
||||||
|
- Challenge: Large-ranging foreground size
|
||||||
|
|
||||||
|
## Training configuration
|
||||||
|
The segmentation of spleen region is formulated as the voxel-wise binary classification. Each voxel is predicted as either foreground (spleen) or background. And the model is optimized with gradient descent method minimizing Dice + cross entropy loss between the predicted mask and ground truth segmentation.
|
||||||
|
|
||||||
|
The training was performed with the following:
|
||||||
|
|
||||||
|
- GPU: at least 12GB of GPU memory
|
||||||
|
- Actual Model Input: 96 x 96 x 96
|
||||||
|
- AMP: True
|
||||||
|
- Optimizer: Novograd
|
||||||
|
- Learning Rate: 0.002
|
||||||
|
- Loss: DiceCELoss
|
||||||
|
- Dataset Manager: CacheDataset
|
||||||
|
|
||||||
|
### Memory Consumption Warning
|
||||||
|
|
||||||
|
If you face memory issues with CacheDataset, you can either switch to a regular Dataset class or lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
|
||||||
|
|
||||||
|
### Input
|
||||||
|
One channel
|
||||||
|
- CT image
|
||||||
|
|
||||||
|
### Output
|
||||||
|
Two channels
|
||||||
|
- Label 1: spleen
|
||||||
|
- Label 0: everything else
|
||||||
|
|
||||||
|
## Performance
|
||||||
|
Dice score is used for evaluating the performance of the model. This model achieves a mean dice score of 0.961.
|
||||||
|
|
||||||
|
#### Training Loss
|
||||||
|
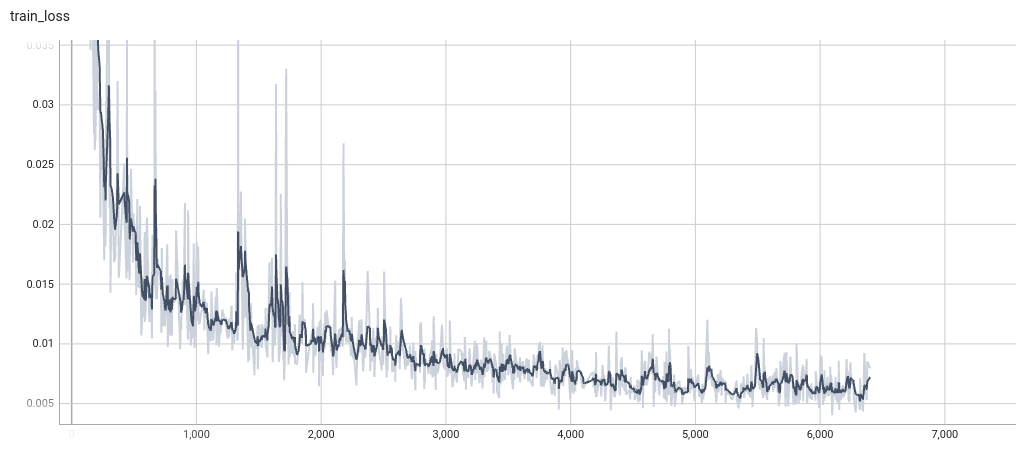
|
||||||
|
|
||||||
|
#### Validation Dice
|
||||||
|
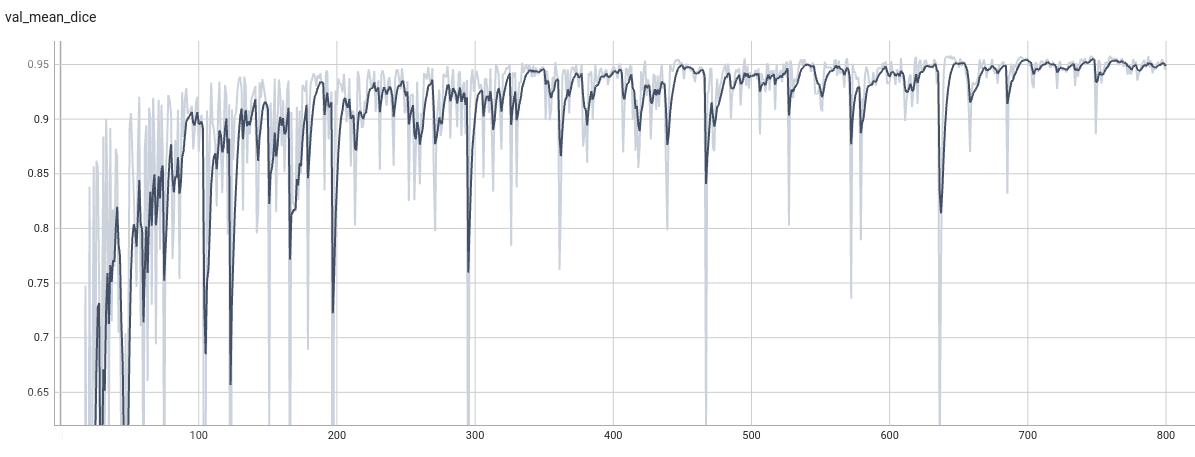
|
||||||
|
|
||||||
|
#### TensorRT speedup
|
||||||
|
The `spleen_ct_segmentation` bundle supports acceleration with TensorRT through the ONNX-TensorRT method. The table below displays the speedup ratios observed on an A100 80G GPU.
|
||||||
|
|
||||||
|
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
||||||
|
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
||||||
|
| model computation | 6.46 | 4.48 | 2.52 | 1.96 | 1.44 | 2.56 | 3.30 | 2.29 |
|
||||||
|
| end2end | 1268.03 | 1152.40 | 1137.40 | 1114.25 | 1.10 | 1.11 | 1.14 | 1.03 |
|
||||||
|
|
||||||
|
Where:
|
||||||
|
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
|
||||||
|
- `end2end` means run the bundle end-to-end with the TensorRT based model.
|
||||||
|
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
|
||||||
|
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
|
||||||
|
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
|
||||||
|
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
|
||||||
|
|
||||||
|
Currently, the only available method to accelerate this model is through ONNX-TensorRT. However, the Torch-TensorRT method is under development and will be available in the near future.
|
||||||
|
|
||||||
|
This result is benchmarked under:
|
||||||
|
- TensorRT: 8.5.3+cuda11.8
|
||||||
|
- Torch-TensorRT Version: 1.4.0
|
||||||
|
- CPU Architecture: x86-64
|
||||||
|
- OS: ubuntu 20.04
|
||||||
|
- Python version:3.8.10
|
||||||
|
- CUDA version: 12.1
|
||||||
|
- GPU models and configuration: A100 80G
|
||||||
|
|
||||||
|
## MONAI Bundle Commands
|
||||||
|
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
||||||
|
|
||||||
|
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
|
||||||
|
|
||||||
|
#### Execute training:
|
||||||
|
|
||||||
|
```
|
||||||
|
python -m monai.bundle run --config_file configs/train.json
|
||||||
|
```
|
||||||
|
|
||||||
|
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
|
||||||
|
|
||||||
|
```
|
||||||
|
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Override the `train` config to execute multi-GPU training:
|
||||||
|
|
||||||
|
```
|
||||||
|
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']"
|
||||||
|
```
|
||||||
|
|
||||||
|
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
|
||||||
|
|
||||||
|
#### Override the `train` config to execute evaluation with the trained model:
|
||||||
|
|
||||||
|
```
|
||||||
|
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Override the `train` config and `evaluate` config to execute multi-GPU evaluation:
|
||||||
|
|
||||||
|
```
|
||||||
|
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json','configs/multi_gpu_evaluate.json']"
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Execute inference:
|
||||||
|
|
||||||
|
```
|
||||||
|
python -m monai.bundle run --config_file configs/inference.json
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
|
||||||
|
|
||||||
|
```
|
||||||
|
python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16> --dynamic_batchsize "[1, 4, 8]" --use_onnx "True" --use_trace "True"
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Execute inference with the TensorRT model:
|
||||||
|
|
||||||
|
```
|
||||||
|
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
|
||||||
|
```
|
||||||
|
|
||||||
|
# References
|
||||||
|
[1] Xia, Yingda, et al. "3D Semi-Supervised Learning with Uncertainty-Aware Multi-View Co-Training." arXiv preprint arXiv:1811.12506 (2018). https://arxiv.org/abs/1811.12506.
|
||||||
|
|
||||||
|
[2] Kerfoot E., Clough J., Oksuz I., Lee J., King A.P., Schnabel J.A. (2019) Left-Ventricle Quantification Using Residual U-Net. In: Pop M. et al. (eds) Statistical Atlases and Computational Models of the Heart. Atrial Segmentation and LV Quantification Challenges. STACOM 2018. Lecture Notes in Computer Science, vol 11395. Springer, Cham. https://doi.org/10.1007/978-3-030-12029-0_40
|
||||||
|
|
||||||
|
# License
|
||||||
|
Copyright (c) MONAI Consortium
|
||||||
|
|
||||||
|
Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
you may not use this file except in compliance with the License.
|
||||||
|
You may obtain a copy of the License at
|
||||||
|
|
||||||
|
http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
Unless required by applicable law or agreed to in writing, software
|
||||||
|
distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
See the License for the specific language governing permissions and
|
||||||
|
limitations under the License.
|
||||||
@ -0,0 +1,6 @@
|
|||||||
|
Third Party Licenses
|
||||||
|
-----------------------------------------------------------------------
|
||||||
|
|
||||||
|
/*********************************************************************/
|
||||||
|
i. Medical Segmentation Decathlon
|
||||||
|
http://medicaldecathlon.com/
|
||||||
BIN
ai-medical/models/spleen_ct_segmentation/models/model.pt
(Stored with Git LFS)
Normal file
BIN
ai-medical/models/spleen_ct_segmentation/models/model.pt
(Stored with Git LFS)
Normal file
Binary file not shown.
BIN
ai-medical/models/spleen_ct_segmentation/models/model.ts
(Stored with Git LFS)
Normal file
BIN
ai-medical/models/spleen_ct_segmentation/models/model.ts
(Stored with Git LFS)
Normal file
Binary file not shown.
13
ai-medical/requirements.ai.txt
Normal file
13
ai-medical/requirements.ai.txt
Normal file
@ -0,0 +1,13 @@
|
|||||||
|
# สำหรับ Model Serving Framework
|
||||||
|
uvicorn[standard]
|
||||||
|
fastapi[standard]
|
||||||
|
# สำหรับ MONAI และ Dependencies หลัก
|
||||||
|
torchvision
|
||||||
|
torchaudio
|
||||||
|
torch
|
||||||
|
pydicom # สำหรับจัดการไฟล์ภาพทางการแพทย์ DICOM
|
||||||
|
numpy
|
||||||
|
scipy
|
||||||
|
monai[all]
|
||||||
|
boto3
|
||||||
|
pydantic-settings
|
||||||
@ -13,6 +13,12 @@ https://docs.djangoproject.com/en/5.2/ref/settings/
|
|||||||
from pathlib import Path
|
from pathlib import Path
|
||||||
import os
|
import os
|
||||||
|
|
||||||
|
# ใน core/settings.py (ด้านบนสุด)
|
||||||
|
from dotenv import load_dotenv
|
||||||
|
load_dotenv() # โหลดตัวแปรจาก .env
|
||||||
|
|
||||||
|
DB_HOST = os.getenv("DB_HOST", "cockroach-1")
|
||||||
|
|
||||||
# Build paths inside the project like this: BASE_DIR / 'subdir'.
|
# Build paths inside the project like this: BASE_DIR / 'subdir'.
|
||||||
BASE_DIR = Path(__file__).resolve().parent.parent
|
BASE_DIR = Path(__file__).resolve().parent.parent
|
||||||
|
|
||||||
@ -192,15 +198,18 @@ DJOSER = {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
REDIS_HOST = os.getenv("REDIS_HOST", "redis")
|
||||||
|
REDIS_PORT = os.getenv("REDIS_PORT", "6379")
|
||||||
|
|
||||||
# 1. ตั้งค่า Redis Cache
|
# 1. ตั้งค่า Redis Cache
|
||||||
CACHES = {
|
CACHES = {
|
||||||
"default": {
|
"default": {
|
||||||
"BACKEND": "django_redis.cache.RedisCache",
|
"BACKEND": "django_redis.cache.RedisCache",
|
||||||
# 'redis' คือ Hostname ของ Service ใน Docker Compose
|
# ใช้ตัวแปร REDIS_HOST ที่ดึงมาจาก .env (localhost) หรือ Docker (redis)
|
||||||
"LOCATION": "redis://redis:6379/1",
|
"LOCATION": f"redis://{REDIS_HOST}:{REDIS_PORT}/1",
|
||||||
"OPTIONS": {
|
"OPTIONS": {
|
||||||
"CLIENT_CLASS": "django_redis.client.DefaultClient",
|
"CLIENT_CLASS": "django_redis.client.DefaultClient",
|
||||||
"IGNORE_EXCEPTIONS": True # ป้องกันการ Crash ถ้า Redis ล่ม
|
"IGNORE_EXCEPTIONS": True
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@ -214,8 +223,8 @@ SESSION_CACHE_ALIAS = "default"
|
|||||||
# CACHE_MIDDLEWARE_KEY_PREFIX = 'auth_cache'
|
# CACHE_MIDDLEWARE_KEY_PREFIX = 'auth_cache'
|
||||||
|
|
||||||
# CELERY CONFIGURATION
|
# CELERY CONFIGURATION
|
||||||
CELERY_BROKER_URL = 'redis://redis:6379/0' # ใช้ Redis เป็น Broker
|
CELERY_BROKER_URL = f'redis://{REDIS_HOST}:{REDIS_PORT}/0'
|
||||||
CELERY_RESULT_BACKEND = 'redis://redis:6379/0' # ใช้ Redis ในการเก็บผลลัพธ์ของ Task
|
CELERY_RESULT_BACKEND = f'redis://{REDIS_HOST}:{REDIS_PORT}/0'
|
||||||
CELERY_ACCEPT_CONTENT = ['json']
|
CELERY_ACCEPT_CONTENT = ['json']
|
||||||
CELERY_TASK_SERIALIZER = 'json'
|
CELERY_TASK_SERIALIZER = 'json'
|
||||||
CELERY_RESULT_SERIALIZER = 'json'
|
CELERY_RESULT_SERIALIZER = 'json'
|
||||||
|
|||||||
34
backend/create_db.py
Normal file
34
backend/create_db.py
Normal file
@ -0,0 +1,34 @@
|
|||||||
|
import psycopg
|
||||||
|
import os
|
||||||
|
|
||||||
|
# --- ตั้งค่าการเชื่อมต่อ (สำคัญ: ต้องตรงกับค่าใน .env) ---
|
||||||
|
DB_HOST = os.environ.get("DB_HOST", "localhost") # ใช้ localhost
|
||||||
|
DB_PORT = os.environ.get("DB_PORT", 26257)
|
||||||
|
DB_NAME = os.environ.get("DB_NAME", "my_db")
|
||||||
|
DB_USER = os.environ.get("DB_USER", "root")
|
||||||
|
DB_PASSWORD = os.environ.get("DB_PASSWORD", "")
|
||||||
|
|
||||||
|
print(f"Attempting to connect to CockroachDB at {DB_HOST}:{DB_PORT} to create database '{DB_NAME}'...")
|
||||||
|
|
||||||
|
try:
|
||||||
|
# ต้องเชื่อมต่อไปยัง Database มาตรฐาน (defaultdb) ก่อน เพื่อให้มีสิทธิ์สร้าง Database ใหม่
|
||||||
|
conn = psycopg.connect(
|
||||||
|
host=DB_HOST,
|
||||||
|
port=DB_PORT,
|
||||||
|
dbname="defaultdb", # ใช้ defaultdb เพื่อสร้าง my_db
|
||||||
|
user=DB_USER,
|
||||||
|
password=DB_PASSWORD
|
||||||
|
)
|
||||||
|
conn.autocommit = True
|
||||||
|
cur = conn.cursor()
|
||||||
|
|
||||||
|
# คำสั่งสร้าง Database
|
||||||
|
cur.execute(f"CREATE DATABASE IF NOT EXISTS {DB_NAME};")
|
||||||
|
|
||||||
|
cur.close()
|
||||||
|
conn.close()
|
||||||
|
print(f"Database '{DB_NAME}' created or already exists successfully.")
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"ERROR: Failed to connect to or create database: {e}")
|
||||||
|
print("Ensure Docker Compose is running and environment variables (DB_HOST, DB_PORT) are set correctly.")
|
||||||
@ -10,3 +10,5 @@ djangorestframework-simplejwt # สำหรับสร้าง JWT (JSON Web
|
|||||||
django-redis # สำหรับเชื่อมต่อ Django กับ Redis
|
django-redis # สำหรับเชื่อมต่อ Django กับ Redis
|
||||||
redis # ไคลเอนต์ Python สำหรับ Redis
|
redis # ไคลเอนต์ Python สำหรับ Redis
|
||||||
celery # ตัว Worker
|
celery # ตัว Worker
|
||||||
|
boto3
|
||||||
|
python-dotenv
|
||||||
@ -87,7 +87,41 @@ services:
|
|||||||
DB_USER: root
|
DB_USER: root
|
||||||
DB_PASSWORD: ''
|
DB_PASSWORD: ''
|
||||||
|
|
||||||
|
# AI Model Serving Service (MONAI Inference)
|
||||||
|
ai_model_server:
|
||||||
|
build:
|
||||||
|
context: ../ # อ้างอิงจาก Root Monorepo
|
||||||
|
dockerfile: infra/docker/Dockerfile.ai
|
||||||
|
container_name: ai_model_server
|
||||||
|
volumes:
|
||||||
|
- ../ai-medical:/app/ai-medical # Map โฟลเดอร์โค้ด AI
|
||||||
|
# - /path/to/gpu/device:/dev/nvidia0 # Uncomment ถ้าใช้ GPU
|
||||||
|
ports:
|
||||||
|
- "8001:8001" # Port สำหรับ API Model Serving
|
||||||
|
depends_on:
|
||||||
|
- backend # ให้มั่นใจว่า Backend พร้อมใช้งานก่อน
|
||||||
|
environment:
|
||||||
|
# กำหนดตัวแปรสภาพแวดล้อมที่ AI Service ต้องใช้
|
||||||
|
MODEL_STORAGE_URL: http://minio:9000/models/
|
||||||
|
MODEL_FILE_NAME: monai_model_v1.pth
|
||||||
|
|
||||||
|
# MinIO Service (S3-Compatible Object Storage)
|
||||||
|
minio:
|
||||||
|
image: minio/minio
|
||||||
|
container_name: minio
|
||||||
|
ports:
|
||||||
|
- "9000:9000" # API Port
|
||||||
|
- "9001:9001" # Console/Web UI Port
|
||||||
|
volumes:
|
||||||
|
- minio_data:/data
|
||||||
|
environment:
|
||||||
|
MINIO_ROOT_USER: minio_admin
|
||||||
|
MINIO_ROOT_PASSWORD: minio_p@ssw0rd!
|
||||||
|
command: server /data --console-address ":9001"
|
||||||
|
restart: always
|
||||||
|
|
||||||
volumes:
|
volumes:
|
||||||
cockroach1:
|
cockroach1:
|
||||||
cockroach2:
|
cockroach2:
|
||||||
cockroach3:
|
cockroach3:
|
||||||
|
minio_data:
|
||||||
Loading…
x
Reference in New Issue
Block a user